


Tekst: ÅgeBA. Innlegget er basert på notater, supplert med informasjon fra andre kilder. Det har vært en tanke med innlegget å gå noe mer i dybden enn foredraget hadde plass til.
Møtet 04.12.2023 hadde tittelen «ChatCPT – utvikling og praktisk bruk av kunstig intelligens», og foredragsholderen med «hands on» erfaring og innsikt i temaet holdt et glimrende foredrag med innlagt bruk av ChatCPT «live».
GPT står for Generative Pre-trained Transformer
Sven Størmer Thaulow v/ Executive Vice President Schibsted Media Group og styreleder i det NTNU-tilknyttede prosjektet NorwAI, et konsortium med store norske bedrifter.

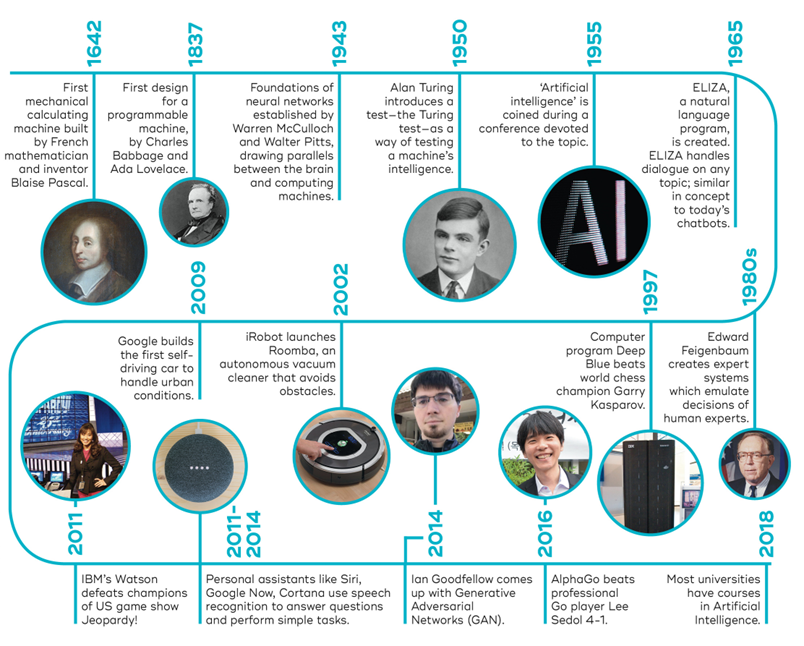
Sven startet med å vise en tidslinje over utviklingen av Artificial Intelligence, og trakk linjene tilbake til bl.a. Alan Turing, mannen med «Turing-testen» og som knekte nazi-Tysklands hemmelige Enigma-kode (glimrende fremstilt i Morten Tyldums film The Imitation Game) og dermed sparte mange liv, bl.a. i den farlige og viktige konvoi-farten over Nord Atlanteren – og WWII ble forkortet med flere år.
{kind=link}
Interessen og optimismen for AI har variert sterkt, siden det berømte seminaret i Dartmouth College, New Hampshire, USA 1956 der begrepet artificial intelligence ble skapt – i mangel av noe bedre.
Man snakker om AI-winters, da resultatene uteble og finansieringen tørket inn.
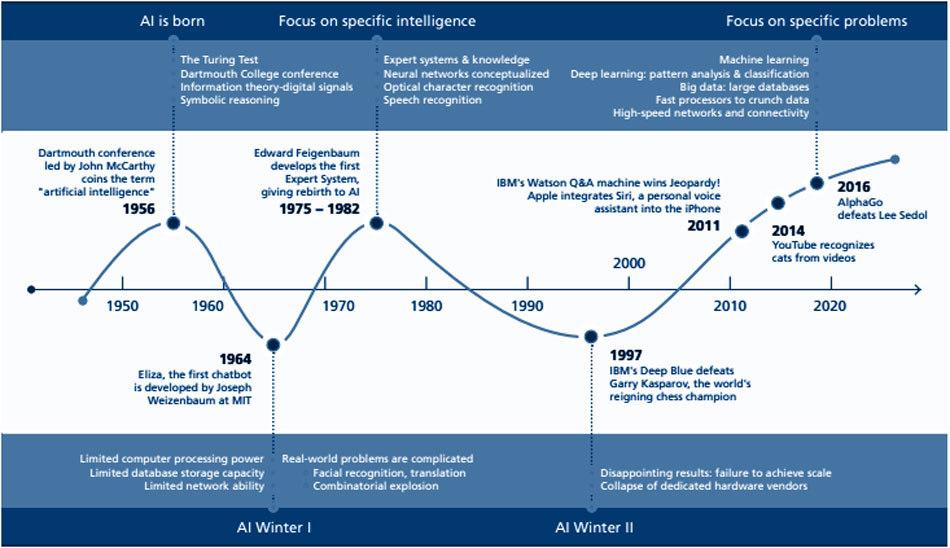
Men med lanseringen av Open AIs ChatGPT, at alle store tech-selskapene kommer med sine AI-systemer, og at antall anvendelser har eksplodert, vil vi neppe se en ny AI-vinter.
Hva er definisjonen på AI?
Kommentar: Det er mange AI-definisjoner å finne ved et søk på Internet, og det er mange begreper som svirrer omkring, se f.eks. denne artikkelen. Her er en enkel fra Merriam-Webster:
- A branch of computer science dealing with the simulation of intelligent behavior in computers.
- The capability of a machine to imitate intelligent human behavior.
AI kategorier
Sven inndelte AI i tre kategorier:
Narrow AI, dvs. AI rettet mot spesifikke oppgaver, f.eks. bankenes bruk for å oppdage svindel; kunnskap oppnådd ved å utføre en oppgave vil ikke kunne brukes på andre oppgaver. Eksempler: Siri (Apple), oversetting (Google Translate), bildegjenkjenning, spam filtre, markedføring basert på tidligere kjøpsadferd (Amazon), selvkjørende biler, sykdoms-diagnostisering.
Generativ AI, dvs AI som kan generere noe nytt (ref. generative), basert på tekst-input, et prompt som omformes til maskinlesbart. Resultatet kan være ny tekst, Excel-ark, programkode, lyd, bilde, video. Eksempler: ChatGPT (tekst), DALL-E (bilder), MusicGen (musikk), Azure Open AI (video).
Artificial General Intelligence, dvs. AI som også har kognitive egenskaper og som (i teorien) kan «tenke» som et menneske – noen mener at slike systemer (i teorien) kan komme til å overgå mennesklig intelligens.
Noen eksempler på AI-anvendelser
Ghostwriter: Skrive Word-dokument med OpenAIs ChatGPT presentert i et Word-sidefelt slik at svarene fra ChatGPT flettes direkte inn i dokumentet og derved slipper man «klipp-og-lim» og å bytte mellom vinduer.
Matematikk: ChatGPT kan løse ligninger (algebra), gjøre beregninger (aritmetikk), statistiske analyse, geometriske konstruksjoner (geometri), differensial- og integralregning – og uoppstilte ligninger (som f.eks. denne: «Tallet er 110. Del tallet i 2 tall som sammen blir 110. Det ene tallet er 150% mer (større) enn det andre. Hvilket tall er det?)
AI narrator som genererer kommentarer til videofilm med stemme tilhørende en person som er avbildet, f.eks. bilde og stemmen til David Attenborough – som Sven demonstrerte i en video der en person drakk kaffe medfølgende kommentarer av «David Attenborough – stemmen».
AI summerizer genererer oppsummeringer av tekst, artikler og essays med de viktigste punktene, og ved hjelp av humata.ai kan man «konversere med et dokument» – stille spørsmål for forklaringer, analysere innhold etc.
Konvertere tekst til tale – få en tekst opplest på ønsket språk med valg av type stemme.
Språkmodeller
Den underliggende teknologien for ChatGPT er såkalte Large Language Models (LLMs). Nøkkelen er store mengder data (ref.large) scraped fra Internett (500 mrd ord for ChatCPT-3) – corpus – bearbeidet og transformert til maskinlesbare enheter, tokens, og et intrikat nettverk av sannsynlighetsberegninger (ref. transformers) samt svært mye datakraft – titusenvis av enheter i neural networks – som er nødvendig for å regne ut sannsynligheter.
Læringsdelen av modellen håndteres av et stort antall maskingenererte parametre (ChatGPT har 1,5 mrd.) som beskriver sannsynligheter for hva som kan være det neste token – del av et ord, et ord eller en frase. Et viktig element er å finne det ordet som skal ha størst oppmerksomhet (attention). Også parametre for å forhindre statistiske skjevheter, uønskede assosiasjoner mellom ord, blasfemi etc. Språkmodellen blir pre-trained.
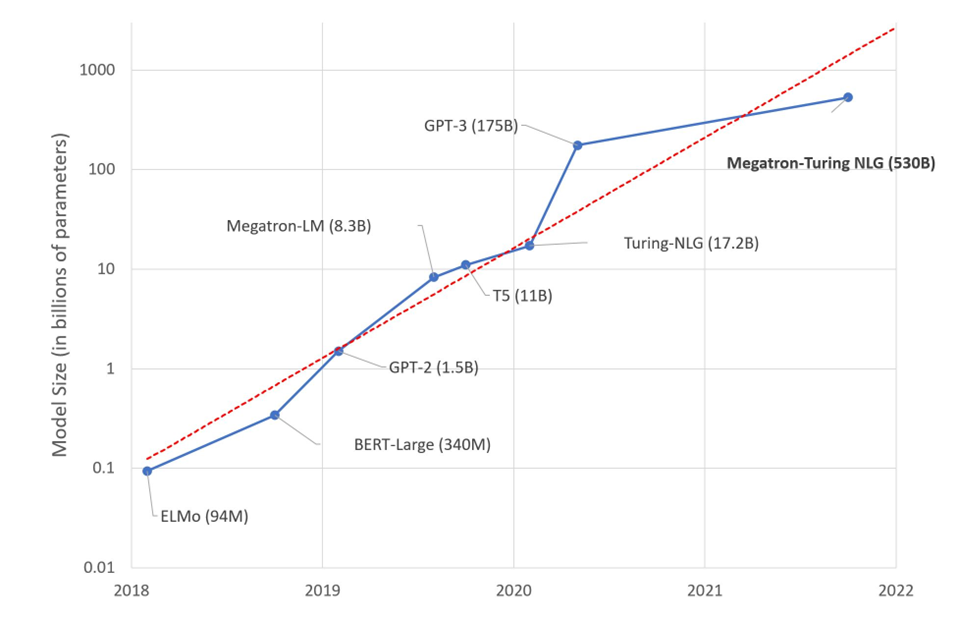
Generering og bruk av språkmodeller krever ekstremt mye datakraft. En vanlig CPU har 6 til 8 cores, mens den nye maskinvare-teknologien GBU (Graphics Processing Units) har 10 000 vis cores. Treningen av ChatCPT-4 foregår på 20 000 cores maskinvare. Nøkkelen er paralell-prosessering og tilhørende gigantisk antall operasjoner.
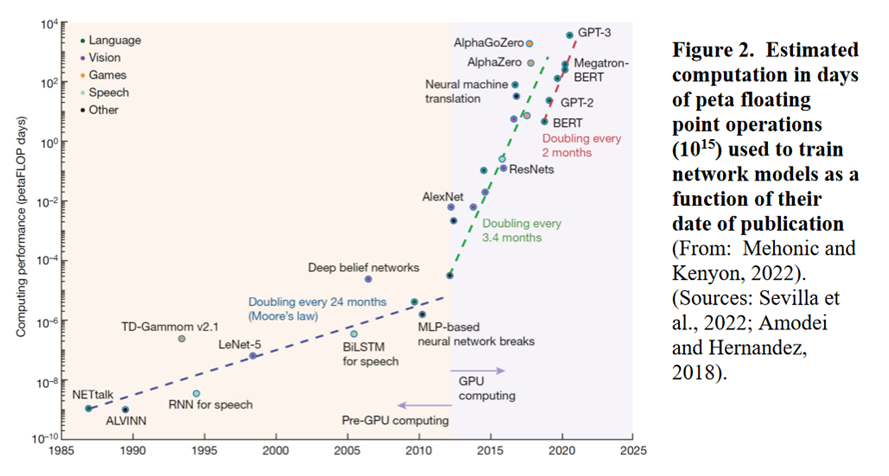
Grafen nedenfor er litt krevende – den viser f.eks. antall maskinelle grunn-operasjoner (FLOP) utført for å skape GPT-3 – målt i peta-FLOP, og den viser betydningen av GPU. Men det krever store investeringer – opp i mot USD 107 for GPT-3 – der kostnaden for elektrisk kraft er betydelig idet å trene GPT-3 modellen én gang krever 1 287 MWh = 1 287 000 kWh, som tilsvarer oppunder 90 års forbruk for en gjennomsnittlig norsk husholdning (14 800 kWh i 2022).
AI svakheter og risiki
- AI, som ChatGPT kan skrive hva som helst, og hva som kommer ut kan være helt absurd (hallusinering), eller bare «fake news«.
- «Noen», dvs. de respektive tech-selskapene, bestemmer hvordan parametre vektes, dvs. hva som er akseptabelt og hva ikke.
- Hva som produseres er avhengig av informasjonsgrunnlaget – dvs, hvor fersk «web-skrapingen» er. F.eks. GPT-3 «vet» ingenting etter september 2021 da treningen stoppet.
- Mye av det som produseres av AI legges ut på Internet, blir også «scraped» og blir benyttet i nye AI-genererte resultater – kvaliteten går ned, kannibalisering.
- «Web-skrapingen» tar ikke hensyn til hverken rettigheter til materiale (copyrights) eller personvernlovgivningen (GDPR).
«Varsellamper» blinker
Maktforskyvning: De store tech-selskapene har allerede mye makt over nasjoner, samfunn og folks liv via (såkalte) sosiale medier – de har skapt systemer som påvirker utfall av demokratiske valg, sympatier og antisympatier mellom folk og folkeslag. AI har potensiale til å forsterke dette i betydelig grad,
Konspiratoriske meninger: Spredning og forsterkning av slike, med «fake news», nå også i manipulerende «fake» bilder, «fake» kommentarer til video med i prinsippet fritt valg av stemmer (ref. eksemplet ovenfor med David Attenborough). Det er mulig å skape bilder av personer i fritt valgte omgivelser og omstendigheter, og legge på fritt valgt tale med personens stemme.
Lovverket er på etterskudd, men EU Artificial Intelligence Act, verdens første forslag til et juridisk rammeverk som spesifikt regulerer AI. Dette er en forordning som gir plikt til alle EU-land å implementere forordningen i nasjonale lover.
Forordningen har vært igjennom en prosess med EU-kommisjonens utkast april 2021, med vedtak i EU-parlamentet 9. desember 2023. Dette innebærer at den trer i kraft sannsynligvis i 2025 eller 2026. Antagelig vil forordningen gjøres gjeldende også i hele EEA, og da vil den bli norsk lov.
NorwAI – utvikling av norsk språkmodell
Det er de store USA-baserte teknologigigantene som er driverne av utviklingen, og språkmodellene er preget av det. F.eks. er GPT-3 trent på ca. 92,5 % engelske ord, fransk – den neste på listen – med 1,8 %, og norsk med 0,1 %.
Fra en artikkel av Sten Størmer Thaulow i Aftenposten 30. juni 2023.hentes følgende:
«Men hva hvis mye av kunnskapen barna våre plukker opp, har basis i amerikanske språkmodeller, som ChatGPT?
Det er i alle fall tre ting vi må tenke på:
- En språkmodell gjør hva den er bedt om å gjøre. Typisk er den satt opp for å estimere de neste ordene i en setning. Den er ikke nødvendigvis laget for å gi riktig informasjon.
- Hva som kommer ut av språkmodellen, vil alltid være et resultat av innholdet den er blitt trent på, og det underliggende verdisettet. Fordommer og normer fra kildematerialet reflekteres i språkmodellen og kan i verste fall gi skadelige utslag.
- Språkmodellene blir også innrettet av de som lager dem. Det betyr at noen bestemmer hva som er uakseptable temaer. For ChatGPTs del er denne grensedragningen gjort i California.»
Ifølge Sten, er det viktige grunner for å utvikle en norsk språkmodell:
- det norske språket – bokmål og nynorsk, også samisk
- vår kulturelle kontekst – vår historie, litteratur, kunst, samfunnsstruktur, styreform, lovverk, etc. etc.
- nasjonal kontroll over egen infrastruktur – det er ikke gitt at AI-teknologien vil være like tilgjengelig i fremtiden
Svaret er altså Norwegian Research Center for AI Innovation – NorwAI. Dette er et konsortium med ANEO, Cognite, Digital Norway, DNB, DNV, Kongsberg Digital, NRK, Schibsted, SpareBank1 SMN, Statnett and Telenor – i tillegg til NTNU, Norwegian Computing Center (NR), SINTEF, University of Oslo and University of Stavanger
